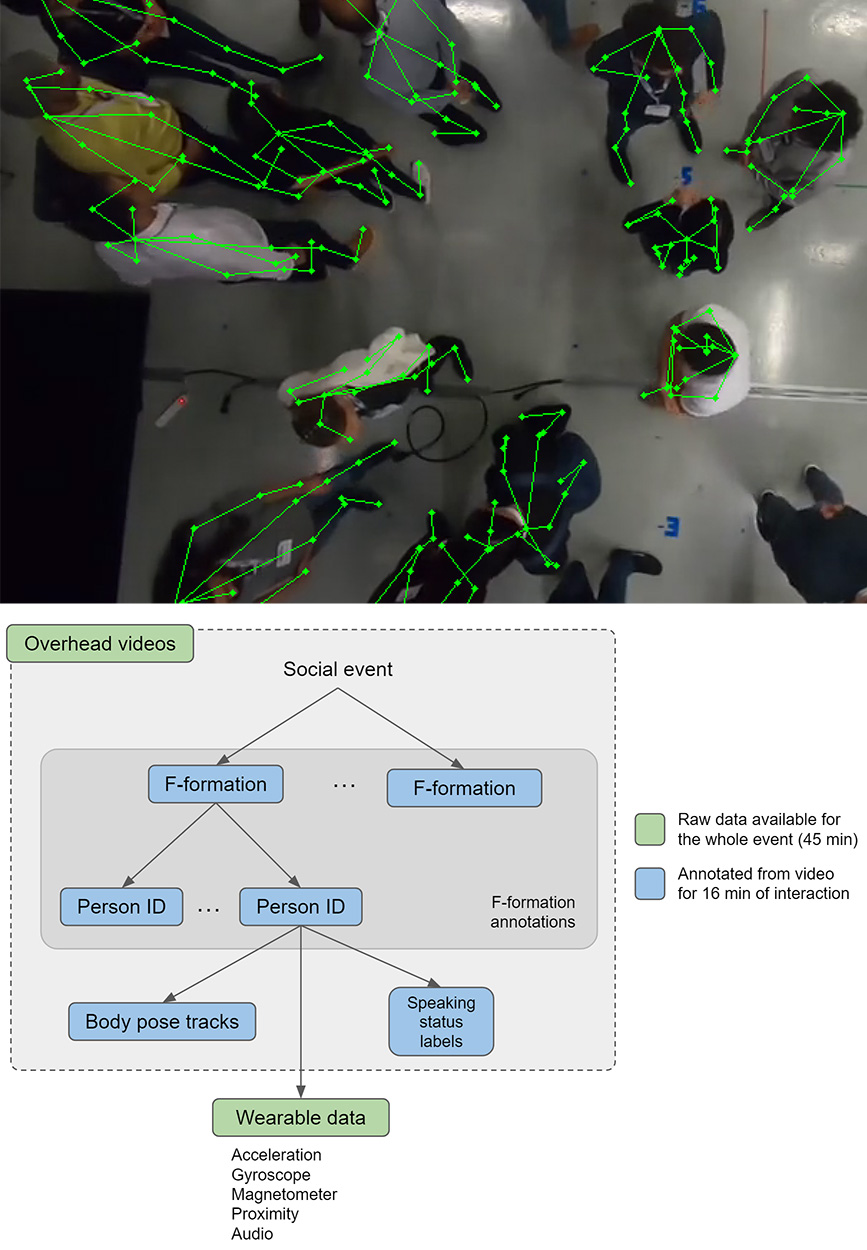
ConfLab is a privacy-sensitive data collection concept and dataset for in-the-wild social interactions. We recorded free interaction of 48 subjects during a networking event at ACM Multimedia 2019. Our capture setup improves upon the data fidelity of prior in-the-wild datasets while retaining privacy sensitivity. We recorded videos from a non-invasive overhead view. Via chest-worn wearable sensors, we recorded body motion (9-axis IMU) low-frequency audio (1250 Hz), and Bluetooth-based proximity.
Our benchmarks tasks showcase some of the open research tasks related to in-the-wild privacy-preserving social data analysis: keypoints detection from overhead camera views (via fine-tuned Mask-RCNN), skeleton-based no-audio speaker detection (vi), and F-formation detection. The ConfLab project resulted in the following publications.
