
About ConfLab
We proposed ConfLab (Conference Living Lab) as a new concept for in-the-wild recording of real-life social human behavior, and provided a dataset from the first edition of ConfLab at ACM Multimedia 2019.
The Dataset
The interaction space with 48 subjects was captured via overhead videos, in which f-formations (conversation groups) were annotated. Each person in an F-formation is associated to their body pose tracks, wearable sensor data, and speaking status labels.


Overhead video
10 overhead cameras
∼ 45 min; 1920×1080 @ 60 fps

Wearable data
Recorded by a badge wearable:
- Low-freq. audio (1250 Hz)
- BT proximity (5 Hz)
- 9-axis IMU (56 Hz)

F-formation annotations (16min)
Annotated at 1Hz for 16 min of interaction.

Full body pose tracks (16min)
Full body pose tracks (17 body joints) annotated seperately per camera (5 cameras) for all participants in the scene.

Action annotations (16min)
Speaking status (binary) annotated continuously (60Hz) for all participants in the scene.

Survey measures
Data subjects reported research interests and level of experience within the MM community.
The ConfLab Template
ConfLab aims to be a template for future data collection in real-life, in-the-wild events through contributions such as the following.


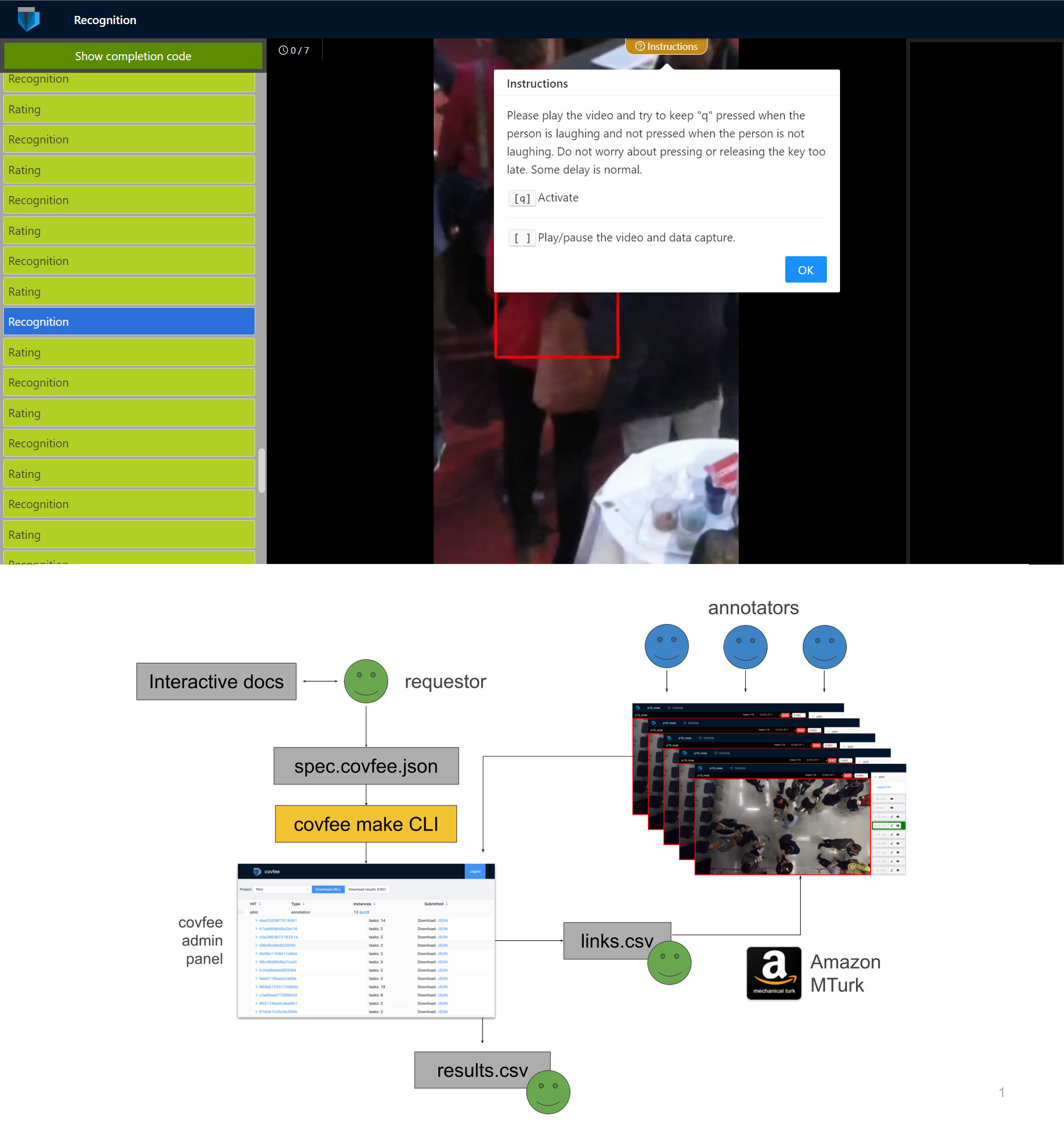
ConfLab is the first large-scale mingling dataset to be annotated for full-body poses. This was possible by using continuous annotation techniques for both keypoints and actions. In pilot studies we measured a 3x speed up in keypoint annotation when using our continuous method when compared to the traditional technique of annotating every frame, followed by interpolation.
The following video shows some of the dataset and annotation interface:
Our continuous methods are implemented and made available as part of the Covfee framework.